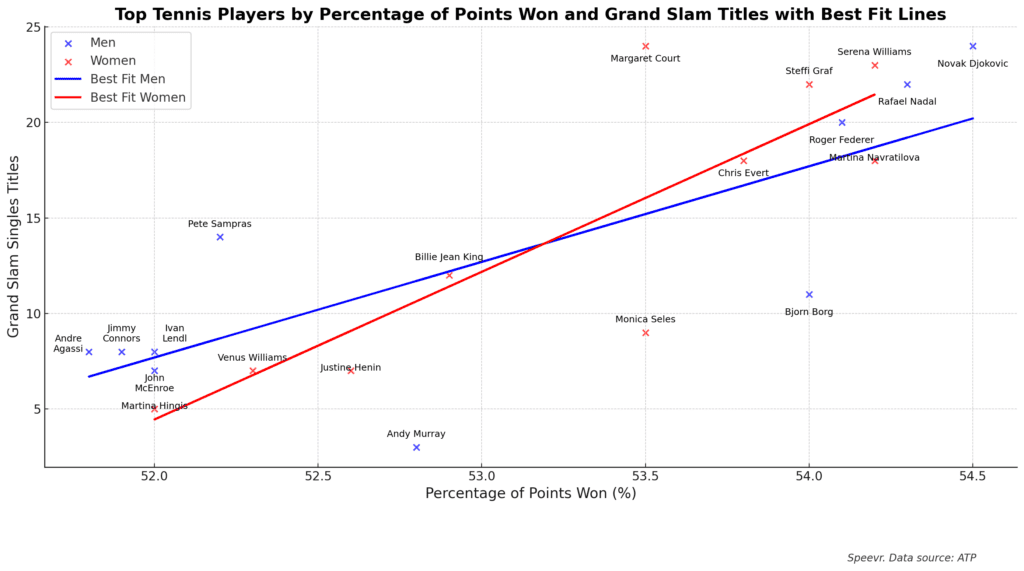
“I'm not saying women are better. I've never said that. I'm saying we deserve some respect.”
— Billie Jean King, Battle of the Sexes
Speevr Intelligence
The Speevr Intelligence daily updates provide in-depth alternative perspectives on key themes and narratives driving financial markets. Our unique collection brings Speevr's exclusive content together with partners' research and analysis.